DataOps Principle #9: Analytics is code
Now how did that get there?… A client asked me about a new column that had appeared in a report. I quickly checked the file and sure enough, the new column was there. I was surprised to see the column, and while surprises are fun for birthday parties, surprises are not my idea of fun at work. I looked at the data lineage and traced it back to a SharePoint list. I was not an administrator on that SharePoint list, but a new column had been added to that list recently and it managed to creep into our model. I talked with the client and removed the column from the model (since it wasn’t required for the reporting).
The issue at hand was resolved, but I knew our team needed a way to avoid this kind of issue in the future. We had been monitoring for refresh issues with Power BI datasets as explained in Part 2, but this type of bug was different because our Power Query code didn’t fail on refresh, but rather introduced a column we did not plan for from a source we did not maintain. We needed a way to identify schema changes before it appeared in production.
DataOps Principle #2: Analytic teams use a variety of individual tools to access, integrate, model, and visualize data. Fundamentally, each of these tools generates code and configuration which describes the actions taken upon data to deliver insight.
In this situation every time a dataset was refreshed, we introduced new data into the model. Based on this principle, we needed to shift our mindset - every time a dataset was refreshed, we introduced new code into the model. And that code needed to be tested. But there are some challenges:
The Challenges
1) Testing Schema Differences – Under “Scheduled Refresh” in the Power BI Service’s dataset, there is no checkbox that if checked would “Fail Refresh If Schema Changes”. If such a checkbox existed a team could be warned of a failed refresh, and the dataset would not introduce untested code.
Figure 1 – If only there was a “Fail Refresh If Schema Changes” checkbox
2) Setting Expectations on the Content - Expanding on Challenge #1, there is no built-in way to monitor for data drift (dun dun dunnnn!). Data Science readers may know this term, but for those unfamiliar with data drift, it is the unexpected and undocumented changes to data structure and semantics. For example, let’s say Column X in Table A was a string column with 20% null values when you deployed it to production for the first time. Over time, the underlying source system caused that string column to report more null values to the point that it contained 50% null values… would you want to know that? I sure would want to know that, and I would definitely want to test for that trend before my customers see it. Or, better yet, I could be transparent and present data drift to my customers (on Power BI of course) so they could understand data quality issues.
3) There are no built-in linters – You may be asking… “Wait a minute John, you mentioned this before in Part 6?” Yes, and Tabular Editor does a great job with evaluating DAX expressions, metadata, model layout, and naming conventions, but does not evaluate the Power Query code (I hope I’m wrong, please someone tell me there is a way to do this in Tabular Editor). More specifically, if we could evaluate our code for say Table.SelectedColumns, we could make sure that certain tables explicitly define the columns that would be used from the source.
A Probable Solution (Work Around)
Alright, so to address Challenge #1, we need to design for a continuous deployment pipeline that (1) conducts a refresh of a Power BI dataset in a staging workspace, (2) tests for schema differences, and (3) “deploys” to the production workspace if no differences are found. Figure 2 illustrates the pipeline, and I will note that this assumes you’re using import mode for the dataset (sorry live connection or direct query folks, but feel free to contact me if you’re trying to do something similar).
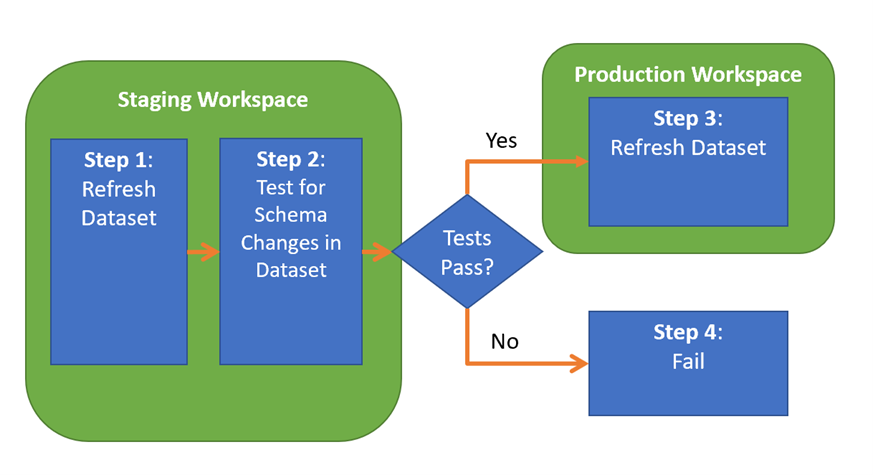
Figure 2 – Continuous Deployment of a Power BI dataset using import mode
Thanks to Azure DevOps we can build such a pipeline based on the previous work we did (see Part 5) to do the following:
1) Refresh Dataset in Staging – Using Power BI’s PowerShell we refresh the Power BI dataset.
2) Test Refreshed Dataset – Using Tabular Editor’s awesome capabilities, we can run a script in the Azure DevOps build agent to extract the schemas from the dataset’s staging version and product version. With the two schemas extracted, we can then compare them for differences. If the schema differs then we issue an error in Azure DevOps (which fails the job). Otherwise, we move to step 3.
3) Refresh Dataset in Production – With confidence that the schema has not changed, we issue a refresh to the production dataset using PowerShell.
I have an example pipeline with install steps shared on GitHub. Please let me know what you think on LinkedIn or Twitter. Stay tuned for my upcoming articles that address challenges #2 and #3 as well (yep, another teaser).