DataOps Principle #17: Reuse
“Don’t lose it, reuse it!”… is a catchphrase from a popular show that my little one watched obsessively for over a year, and that catchphrase has been seared into my brain. Unsurprisingly, that catchphrase would repeat in my head after reviewing several Power BI datasets. Our team had created several custom functions in Power Query and they were being used across datasets. While I was pleased to see custom functions were being embraced, ensuring that these functions were being properly reused across datasets and managed was whole other ordeal. Within the first two months of our team embracing custom functions, we had spent several hours copying updated M code for custom functions into various datasets. This was an unacceptable use of their time, and we needed a methodology to rescue us from the copy-and-paste firestorm that lurked just around the next update.
DataOps Principle #17: We believe a foundational aspect of analytic insight manufacturing efficiency is to avoid the repetition of previous work by the individual or team.
The Challenges
As I have growled before, sometimes bringing patterns involving high-code (in this case code reuse) to a low-code tool can be challenging. Applying the reuse principal was not an exception, and we quickly identified some challenges:
1) Version Control – While the custom functions were a part of the dataset and were being versioned using the techniques in Part 3, the custom functions themselves represented something that could be used across datasets. How could we make sure staff were using the appropriate custom functions and avoid having to manually inspect each dataset for differences in the code? And how do we avoid copy-and-paste updates?
2) Package Management – A lot of our custom functions could be logically grouped together like global M functions (Table, Text, Number, etc.). Was it possible to do that with a group of custom functions? Was that the right approach?
3) Package Dependencies – If we could solve the version control issue, how could we make sure datasets upgrade to different versions of the custom functions on our own schedule? For example, if I had version 1.0 of Custom Function A running on Dataset B, how would I make sure when version 2.0 of Custom Function A is released that Dataset B does not automatically switch to 2.0 on the next data refresh without testing?
4) Documentation – While the name of the custom function could be self-explanatory, how could we make it easier for our team to understand the parameters and possible considerations when using a function?
The Research
With all the questions in front of us, I scoured articles on the sites of the Power BI community I knew and tried to sniff out patterns they used to reuse custom functions. Throughout this section I’ll try to reference who provided these patterns, but I will admit these references are not exhaustive and those that I reference may or may not be the original provider of a pattern.
Version Control
This was an easy pattern to identify; Git was the solution. I first came across Curbal’s video for Reusing Functions and quickly found that other community members like Maxim Zelensky, Imke Feldman, and Igor Cotruta stored their Power Query functions in Git.
Package Management
Throughout my search, I found three patterns of packaging custom functions:
Function import – from library import function_x, function_y
With this pattern you only bring in the custom functions you need from Git. More specifically, each Power BI file has a custom function that fetches the code from Git, a “load” function. For example, Kiara Grouwstra’slibrary has a LoadFunctionFromGithub.pq function that will pull another custom function from GitHub and add it to the model.
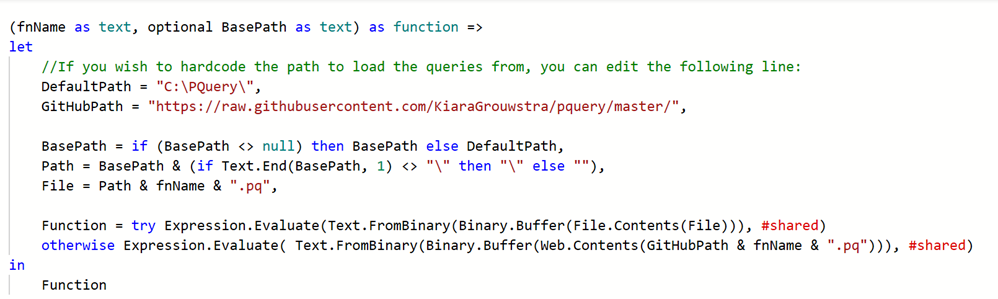
Figure 1 - LoadFunctionFromGithub Power Query Snippet
The downside to this approach is the function is named with a default value (Invoked Function) and you still need to rename the function.
Module import – from library import *
With this pattern you bring in all the functions using a similar load function, and then you choose which ones to add by clicking the function link and selecting “Add as New Query” (see Figure 2). I came across this pattern from Kim Burgess’ m-tools library.
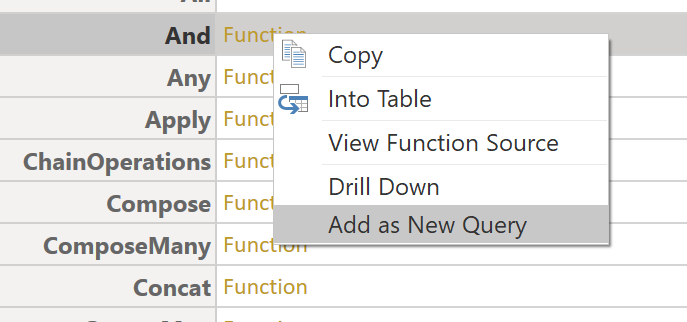
Figure 2 – Choose a function from a whole library
The nice thing about this approach is the name of the function is automatically added, so no manual renaming is required!
.mez Maneuver
I found this approach from Eugene Meidinger’s article and Igor Cotruta’s library and it involves using the PowerQuery SDK to build a Custom Connector that packages the custom functions. This pattern involves compiling the custom functions into zip files with a .mez extension (who names these extensions?). To leverage locally, you need to have the .mez files in the Custom Connectors folder. Unfortunately, this presents a fun message:
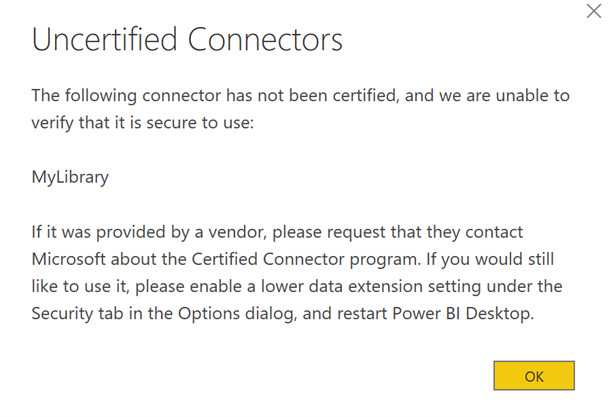
Figure 3 – Yikes, that’s not a fun message.
There is a way to turn it off, but if you have security reviews on your Power BI projects this may require some explaining.
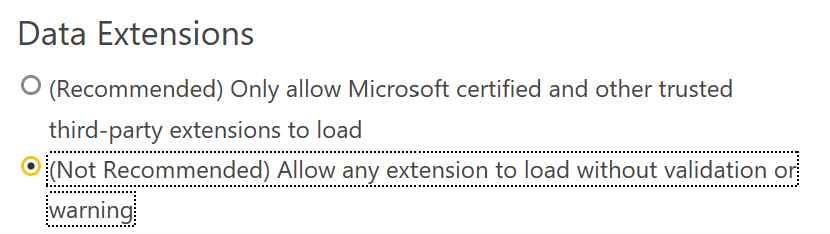
Figure 4 - Not Recommended? This should be fun to explain to our InfoSec team.
To leverage in the Power BI service, you also need to have a gateway with the custom connector installed. For some projects, getting a gateway installed or convincing admins to install a custom connector may be a non-starter.
Package Dependencies
If you have worked with yarn or pipenv, then this concept is not new to you, but I’ll provide a brief explanation. Let’s say you have a custom function in the master branch of your repository with two parameters Foo(x as text). You want to improve Foo by adding another parameter y and with your new logic this parameter is not optional. If you were to update the master branch with the new Foo you would break any Power BI report using this function on their next refresh and see a message like this:

So how do you prevent this? I didn’t see many examples out there, but if we use Git and the Function/Module import pattern, then the Load function could be updated like this:
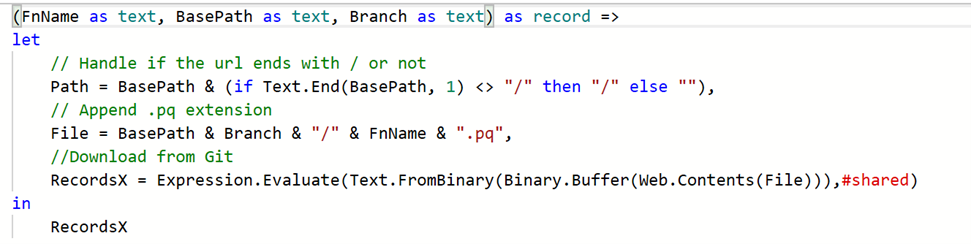
The branch parameter allows you to define which version of the code to import. Consequently, you could have a parameter in your model that defines what branch to use, update the parameter, fix anything that breaks, test, and redeploy your model confident that the new version of the custom function works.
Side note: If you see the #shared keyword in the code above and don’t know what it means, don’t fret, Imke Feldman and Lars Schreiber are on the case and have an excellent series explaining #shared and the environment concept.
Documentation
Very early on in my career I was told that documentation and code comments was like cleaning the guest bathroom. It’s a pain to upkeep, but others will surely appreciate its cleanliness when they visit. So how could you properly comment your custom functions? Well, I didn’t know this was even possible with custom functions until I saw this Imke Feldman function:
This is a great pattern to emulate and you can see how Imke accomplishes this by looking at an example here.
My Thoughts
While there are several options with both pros and cons depending on your environment, I settled with this pattern for my typical projects moving forward (until a better pattern or patterns emerges):
Version Control: Git
Package Management: Module import – from library import *
Package Dependencies: My own flavor of the Load function
Documentation: Imke’s pattern.
Conclusion
I tried to exemplify the patterns I found in my research in a Power BI file that is available for download at this link. As always, if you have any thoughts on this article, have a pattern I didn’t see, or corrections/solutions, just yelp for help on LinkedIn or Twitter.