DataOps Principle #14: Analytics is Manufacturing
“Patience is a virtue”… I am not a patient person. Red lights at traffic stops vex me when there is no cross traffic. If I see long queues at restaurants, I’m more likely to avoid the place all together because I don’t want to wait. I have a lot to learn about patience when I cannot control the situation. On the other hand, at work where I do have some control, I can focus my impatience on process improvements!
DataOps Principle #14: Analytic pipelines are analogous to lean manufacturing lines. We believe a fundamental concept of DataOps is a focus on process-thinking aimed at achieving continuous efficiencies in the manufacture of analytic insight.
The Power BI development lifecycle and the Azure Pipelines that support continuous integration and deployment is also analogous to manufacturing lines. If you’ve tried implementing Part 5, Part 6, or Part 8 of my blog you may have noticed the checks I put in place to install PowerShell modules, Tabular Editor, and Analysis Management Objects (AMO) when needed. That’s because as of October 3rd, 2021, the images available as a Microsoft-hosted agent do not have all the dependencies pre-installed to run the pipeline. This appears to lengthen each run because certain installations must occur before further steps in the pipeline can execute. But how much more time is taken dealing with these dependencies and installations?
The Questions
Thankfully, Azure DevOps offers the ability to create self-hosted agents to install the prerequisites and adjust processing power to see if efficiencies can be gained. Many reading this may say, well of course a properly configured self-hosted agent would run the pipelines quicker. I would tend to agree with you, but that does not necessarily follow the principles of DataOps. We need to show empirically that efficiencies are gained and demonstrate a return on investment in self-hosted agents. As a result, we will gather data to answer the following questions:
- How much faster can a self-hosted agent run versus a Microsoft-hosted agent?
- If we can create a self-hosted agent with 7GB of RAM and 2 virtual CPUs (the standard for a Windows image on a Microsoft Hosted Agent) how much faster does it run?
- If I increase RAM or virtual CPUs by 50% is there a gain in performance?
- Is the cost for running a self-hosted agent cheaper than having staff not wait for pipelines to run?
- If so, how often must the pipeline run to realize savings?
By answering these questions, a team can confidently move forward or pull back on pursuing self-hosted agents.
The Experiment
The architecture layout for this experiment is illustrated in the Figure below. The Resource Group, Containers, Container Registry, and Docker are highlighted in yellow to show the newest components to the layout since Part 5 of this series.
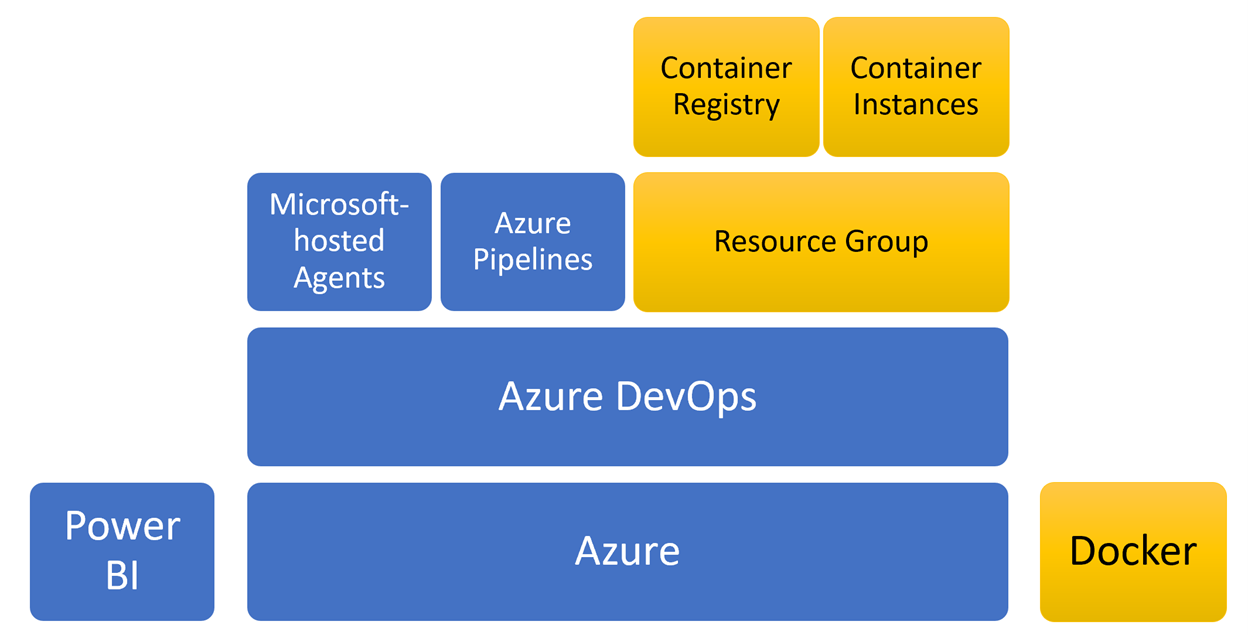 Figure 1 – Components of the experiment for self-hosted agents
Figure 1 – Components of the experiment for self-hosted agents
I chose to use Azure and containers for hosting and running self-hosted agents respectively. My familiarity with Azure influenced me to choose this cloud platform, but if you’re interested in recreating it in Amazon, Google Cloud, or another cloud, please reach out to me as I would love to see the results when the cloud platform variable changes.
In the GitHub repo, I provide step-by-step (hopefully) instructions to run these tests, but I would like to provide the following details/comments on a few components:
Resource Group – The resource group hosts the resources we need to create the self-hosted agents and is located within the same region where the Azure DevOps instance is located. Since network latency is a variable, I tried to mitigate variability (since I can’t physically touch the network cables) by keeping the self-hosted agents in the same location.
To find where your Azure DevOps instance is located please follow these instructions.
Docker – Using the Microsoft instructions as a basis, Docker is used to instruct images to install the prerequisites for running an Azure Pipeline and install the PowerShell modules, Tabular Editor, and Analysis Management Objects.
Container Registry – Once the Docker image is created, the image definition should be hosted in a registry in order manage the Docker images. This experiment follows DataOps principles so if self-hosted agents are worthwhile, we should treat Docker images as code and make them easier to manage/reuse.
Container Instances – Also known as the self-hosted agent, this is where most of the pipeline work is done. For the purpose of the experiment, there are two container instances, at 7GB RAM/2vCPU agent to try match the Microsoft-hosted agent, and a 10.5GB RAM/3vCPU agent with 50% more memory/processing resources.
Experiment in Action
The experiment runs three different agents, the Microsoft-hosted agent, the self-hosted agent with similar resources (7GB RAM/2vCPU) and a self-hosted agent with 50% more resources (10.5GB RAM/3vCPU). Each agent runs the Continuous Integration job that includes Part 5 and Part 6 of this series as well as the Low-Code Coverage job from Part 8. To gather data, the YAML file that runs the pipeline is scheduled to run every 20 minutes. After a 24-hour period we should have enough data to analyze and answer questions.
Learning What Not To Do
To be honest, the pursuit of these answers was not easy. I spent more time than I care to admit learning several ways not to do things and the one way that worked consistently (relatively). With that said, I’d like to share a couple of roadblocks I hit so that you may learn from my mistakes, or at least not feel discouraged if you encounter them yourself:
1) Setting up Docker on a Windows machine was frustrating. It was only after setting up a Windows Server following these directions and going the Hyper-V route (instead of WSL 2) did I successfully create the self-hosted agent.
2) I had to create a mix of Azure CLI, Docker, and PowerShell commands to make this effort reproducible. This was because an API may have a feature that another API didn’t have, or one API was easier in implementing a task than the others. For example, I ended up calling the Azure DevOps REST API via Invoke-WebRequest because the Azure DevOps extension for Azure CLI did not have a command to create agent pools. In addition, scripting the creation of containers was far easier in PowerShell than Azure CLI. I felt a little like Dr. Frankenstein grafting together different APIs to build a monster codebase.
Alright, so if you missed it above, the instructions to run this experiment can be found at this link on GitHub. In my next article, I’ll share how to take the data stored on Azure DevOps and come to some conclusions leveraging Power BI (I can’t help myself). And if that isn’t exciting enough, the next article will provide examples of how to query Azure DevOps’ API using Power Query, so you may find that topic interesting. I won’t have any tips on improving your patience because I’m still working on that. In the meantime, please let me know what you think on LinkedIn or Twitter.