DataOps Principle #7: Reduce heroism
“You saved the day!”… one of our clients told my teammate. We had attended a meeting with our clients and their bosses reviewing one of the latest Power BI reports we had deployed. Important decisions were being made with the data, and one of my teammates had the foresight to make a copy of the underlying Power BI dataset and store it before it is refreshed. Their thinking was that questions may arise about the data at the time those decisions were being made; therefore, the client needed a reliable way recall the data. Naturally two weeks later, questions from other leadership started circulating concerning the decisions that were made and the data used to make those decisions. When our clients consulted us, our prophetic teammate spoke up and provided a link to the copy of the data on a OneDrive folder. Our teammate deserved a cape and capital P (for Power BI of course) emblazoned across their chest… a hero.
I was very thankful for our teammate swooping in to save the day, but just like a popular animated series about heroes, I couldn’t help but wonder what if? What if that teammate was not present at the meeting? What if our team wasn’t around to make that back up?
DataOps Principle #7: As the pace and breadth of need for analytic insights ever increases, we believe analytic teams should strive to reduce heroism and create sustainable and scalable data analytic teams and processes.
After that event, I talked with our team to discuss how we could empower our client to run their own backups. First, we looked at the parameters we were working in:
1) Office 365 E3/Premium Per User Environment – We had to operate within the bounds of the current licensing setup, and additional resources like Premium or Azure were not possible. Also at the time, Backup and restore datasets with Power BI Premium had just entered preview and if you read Part 7 of my series that option was not yet production ready.
2) Ease of Use – We need to give our clients the ability to kick off a backup and easily retrieve it so it could be integrated in their environment.
3) Import Only – Our dataset was developed using the import mode, so we knew all the data was contained with the dataset as a snapshot in time.
Second, we looked at our options, and decided on a route: Power Automate and SharePoint. We could create a flow that our client could run and using Power BI’s Export to File API endpoint we could let flow run the backup and save it to a SharePoint site managed by our client.
Since I came from the SharePoint world before moving to the Power BI world, I volunteered as tribute to create the Backup Flow.
The Setup
Having worked with Microsoft Flow before it became Power Automate, I knew the HTTP connector that we could use was not available under the current licensing model. Back in 2019, Microsoft had introduced a wonderful challenge in my life by moving that connector to premium status. I spent weeks explaining a convoluted licensing framework to clients, and in the end I just rearchitected several solutions due to a lack of funding anyway. So, now that I am older and wiser (thanks to those wonderful challenges) I knew that a better route was a Custom Connector and not the HTTP connector. If you’re interested in how to setup a Custom Connector, there have been many blog articles written on the topic. Konstantinos Ioannou’s article and Chris Webb’s article are two that I have bookmarked and refer to for guidance.
After half-a-day, I had a flow that looked like this:
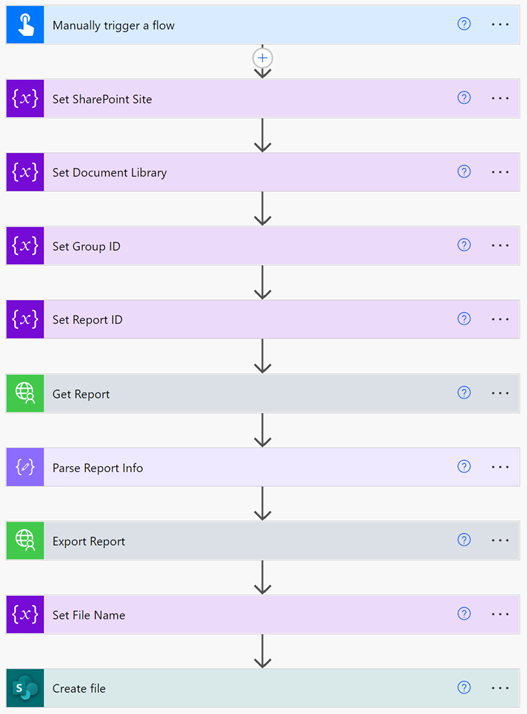
And it worked! We tested it with our production datasets and didn’t run into any issues and after a few days the clients were trained on how to use the Backup Flow.
Blog article done, right? Nope, I just had to adhere to DataOps principles and sure enough I ran into some issues. Issues I was glad I ran into before our clients did.
Making it Reproducible
With this principle in mind, I wanted to make sure the Custom Connector and Flow could be stored in version control and make it easier to deploy to other environments (dev, test, prod). So, I ventured into the world of using Microsoft Power Platform CLI to deploy the Custom Connector. And that’s where the trouble started. I needed to install Python, just another prerequisite to the already growing list of prerequisites needed to script deployments. I found myself using the self-declared APP stack (Azure CLI, PowerShell, Python) to script out the following:
1) Create an Azure App Service Principal with the appropriate delegated permissions to Power BI.
2) Update the Custom Connector’s apiProperties.json file with client id of the new Azure App Service Principal.
3) Deploy the Custom Connector using the CLI. This includes providing a client secret from the Azure App Service Principal.
Step 3 was where I really hit a wall. This one-line of code was my roadblock for several days:
paconn create -s "settings.json" -r $CredentialResult.password
After determining that it may not be my fault, I went to the GitHub page for the CLI code and found this issue. Thanks to Nirmal Kumar I was informed of a work around that involved a minor change to the apiProperties.json file:
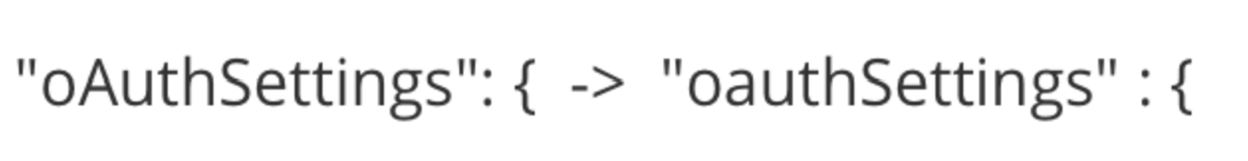
Did you see the change? A lowercase ‘a’ instead of an uppercase ‘A’! Arrrgh!
I was very thankful for the fact that the open-source community allowed for information sharing, but equally frustrated that this wasn’t tested. It seems like such an important part of the tool.
With that roadblock out of the way, I finished the script. I loaded the script on GitHub and the Flow on GitHub as well. I don’t have any readme instructions, and we’ll get to that reason shortly.
Monitor quality and performance
From my experience with SQL backup jobs, I knew that if not properly monitored a backup job could easily fail and go unnoticed, or take longer and longer to complete over time causing data pipelines to be impacted. The current Backup Flow worked, but how would it fair if I increased the size of the data model?
I then set forth with a small dataset, increasing it by about 10 MB and running the Backup Flow. At around 20MB the Flow started to fail with this message:
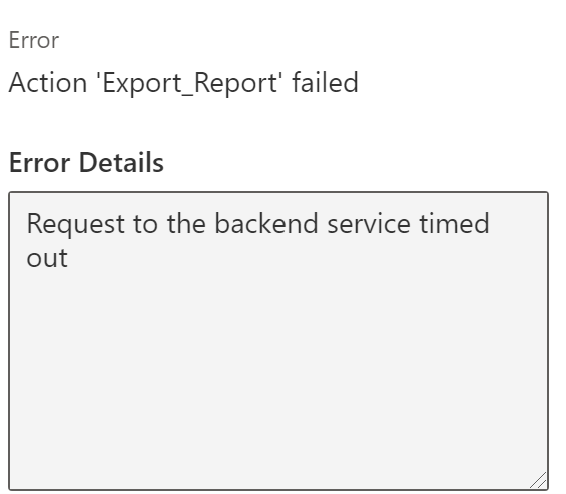
So, my inclination was valid, and I quickly warned our client of the possible failure and work around (export via Power BI Service). Now I needed to find out why the timeout occurred. It turns out a Custom Connector has a two-minute connection timeout. Alright, so this whole Backup Flow idea works up to a point and when you reach around 20MB for a dataset, you’re out of luck with this option. Thus, no readme instructions because I wouldn’t necessarily recommend this approach. This was a learning experience for me, and I hope you learn from my cautionary tale and become wiser without getting older.
PreferClientRouting
Note: As of November 16, 2021 the issue in this section does not appear on the East2 tenant (hurray!), but I will keep it in the blog for sentimental purposes.
What did we end up doing to replace the Backup Flow? I thought Power BI PowerShell would allow us to come to the rescue. But when I tested Export-PowerBIReport with large files, I would get a 500 internal server error. I then tried the Invoke-PowerBIRestMethod route using the Export Report in Group and got the same 500 error. Alright, as a sanity check I tried to download the pbix files I was testing using the manual method. They worked just fine (head scratcher).
It was now time for me to read some documentation. Mercifully, at the top of the documentation or Export Report in Group there was this message:
Note: As a workaround for fixing timeout issues, you can set preferClientRouting to true.
Large files are downloaded to a temporary blob. Their URL is returned in the response and stored in the locally downloaded PBIX file.
After digging a little deeper, if I used the preferClientRouting parameter there should be a 307 redirect with a location header identifying the temporary URL for the pbix file.
So I appended “?preferClientRouting” to the API call via Invoke-PowerBIRestMethod and got a 403 Forbidden error. I then turned to Google and GitHub to see if anyone has faced this issue… no luck. At this point I reached out to folks on Twitter and I posted an issue on Microsoft’s Power BI PowerShell GitHub. Since I’m stubborn and impatient, I didn’t wait long to break out Postman to see how the Power BI API was behaving. Then I opened developer tools on Chrome, and looked to see what network requests occurred when we tried downloading a pbix through the manual method.
What I have discovered is the redirect URL provided by the API in the 307 response is inaccessible. However, the URL that works via the manual method is at the same host (ex. https://wabi-us-east2-b-primary-redirect.analysis.windows.net) but at a different endpoint “export/v201606/reports/{Report ID}/pbix”. Okay, now we’re getting somewhere.
After a couple hours I update the PowerShell using the new endpoint (which works with the bearer token) and successfully test downloads up to 100 MB. Shazam!
Note: This seems to be only an issue on the commercial Microsoft tenants I’ve tested and, yes, I have opened a support issue at https://support.powerbi.com.
Conclusion
After some instruction and SOP updates, our clients could run this PowerShell themselves and we were more confident this process would work. So, I’m content to say that after they got the hero they wanted, they got a process they deserved (oh you knew that was coming).
If you’re interested in downloading the PowerShell script it is available at this link. As always, if you have any thoughts on this article or corrections/solutions, please let me know what you think on LinkedIn or Twitter.