Distractions, DataOps, and Documentation
If you have read Part 1 of this series, you probably know that I like to listen to podcasts while I go running. To help pass the time, I was happy to listen to a recent DataTalks.club podcast where there was a recent episode in which Alexey Grigorev and the audience asked questions of Chris Bergh, the Father of DataOps. This was a wonderful distraction on my run as I listened to Chris explain that teams/organizations should be focused on optimizing from the perspective of the whole system; the data, the model, the visualization, and the governance. DataOps comprises principles of Lean Manufacturing, so those familiar with Lean would call this Optimize the Whole. When we balkanize this optimization, and this is very easy to do when you have large organizations (one in charge of data engineering, one in charge of the business line, one in charge of enterprise architecture, etc.), we risk losing the ability to deliver value because the separate parts consider done/success differently. For the data engineers “done” might be getting the ETL job to complete on time, but are we delivering value when the transformed data is of bad quality?
Near the middle of my run, Chris and Alexey further discussed focus areas when applying the principles of DataOps:
Lowering errors in production – Track and prevent errors from the data source all the way to where it creates value, including all the different tools and code that move and transform the data.
Reduce cycle time to deployment – Deliver features/updates quicker for the customer.
Productivity of the team – Empower your team to get their work done right, quicker.
Measure – You can’t see progress without tracking items 1, 2, and 3.
This discussion really struck me because earlier in the day I was reading a new article on advance data model management in Power BI’s implementation planning documentation and I homed in on this visual from the article:
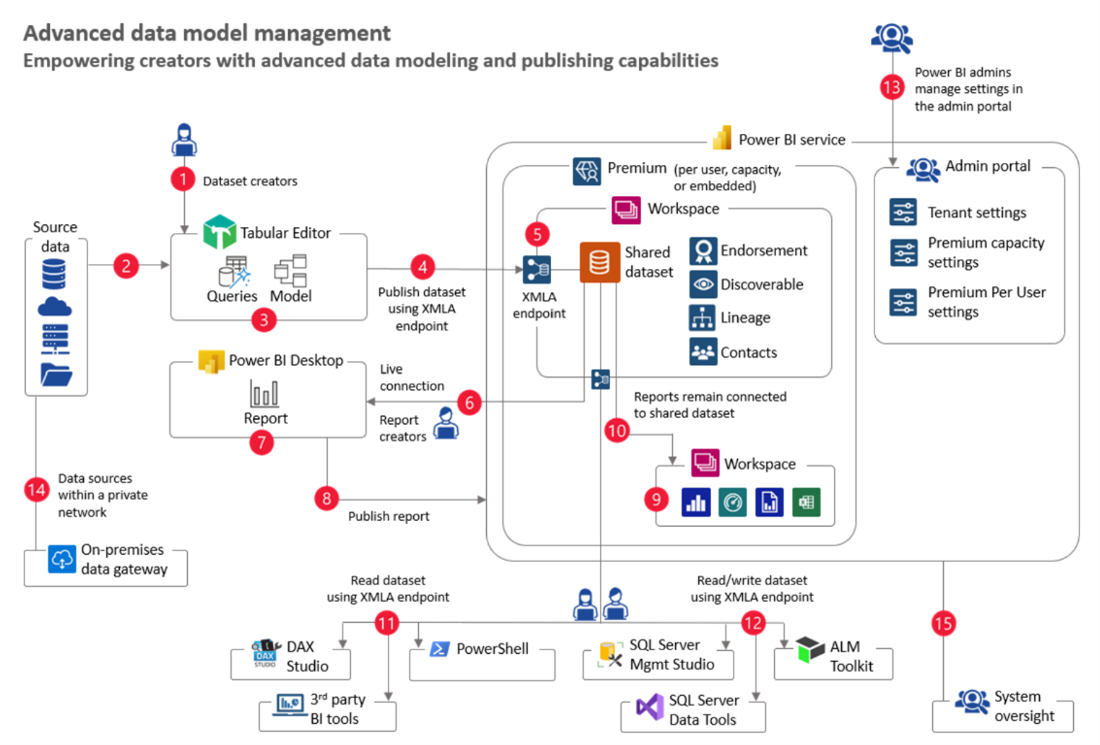
Figure 1 – From Microsoft Documentation - Usage Scenario: Advanced Data Model Management
With my DataOps glasses on, I was not able to see where we could show clients/customers how all these relationships are delivering value. I agree that external tools, right now, are required to do advanced data model management, but project teams are often challenged with:
Proving that these external tools and their potential license costs deliver value and are worthy investments either in money or the time involved to go through a bureaucratic process of getting them approved and installed.
Proving that the code acting on the data, and the data itself is of high quality.
So if I could append this article, I would recommend that when looking at advanced data model management you keep in mind the following based on the items (red circles) from that visual:
| Item | John’s DataOps Thoughts |
|---|---|
| 2 |
|
| 4 & 6 | Your team should find ways to answer “yes” to these questions:
|
| 14 |
|
| 15 |
|
| All |
|
Now it is time for the shameless plug. If you are looking for way to implement the thoughts I presented or the DataOps principles in your Power BI project I have some ideas from this series and code to share. I know that I do not have all the answers, but I do hope you read these ideas, discuss them with the Power BI Community, and that this eventually leads to 3 outcomes:
Whether you call it DevOps, MLOps or XOps you see how applying the principles in the DataOps Manifesto will make delivering Power BI solutions better.
Because you have better solutions, you spend less time babysitting data models or fretting about issues with Power BI projects and can spend more time with family, take a vacation, or go for a longer run (Reduce heroism).
Enough attention is given to the product gaps in bringing these principles to Power BI that they become new features within Power BI and we ultimately make many of my blog articles obsolete.
For #3 I am excited to read recent news that Power BI reports/datasets will begin to be incorporated into the Power Platform’s Application Lifecycle Management in July 2022. This could be a great first step, and I’ll be sure to share my opinions on this blog.
And if you’re looking for other ideas around this topic, I suggest following Daniel Otykier and GreyskullPBI on Twitter if you don’t already.
What do you think? Did I miss the point of the Power BI article? Am I weird for listening to podcasts while I run? Let me know your thoughts on LinkedIn or Twitter.