Quality is Paramount and the Cell-Level Error
Cell-Level errors (like the one in Figure 1) are things of nightmares to me. You feel confident about the dataset when you move it to production, and, for a while, everything goes according to plan—until it doesn’t. You hear something is wrong, and upon inspecting the data, you realize some of your custom columns have generated cell-level errors.
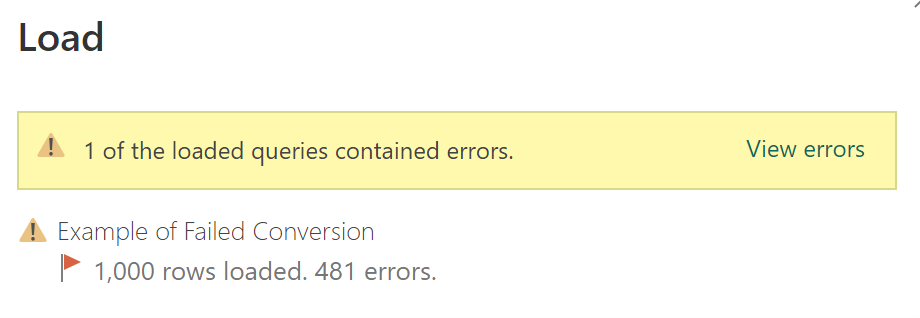
Figure 1 - Example of a cell-level error.
Microsoft states in their documentation: “A cell-level error won't prevent the query from loading, but displays error values as Error in the cell. Selecting the white space in the cell displays the error pane underneath the data preview.”
To extend this definition, “A cell-level error won’t prevent the query from loading,” but a blank value will appear in the dataset. As an example, Figure 2 illustrates a custom column that performs the function Number.FromText using the value from the second column. When the value of the second column is two, the Number.FromText function fails because it expected a numeric value (i.e., 2).

Figure 2 - A cell with a cell-level error appears blank in the model.
A common culprit for this issue is data drift, the unexpected and undocumented changes to data structure and semantics. While you may not be responsible for or have authority over the upstream data that feeds into your dataset, who do your customers blame? You.
So how do we avoid the dreaded cell-level error? It starts with embracing a DataOps principle: Quality is Paramount. This principle states:
Analytic pipelines should be built with a foundation capable of automated detection of abnormalities and security issues in code, configuration, and data, and should provide continuous feedback to operators for error avoidance.
As shown in Figure 3, working with Power BI in an analytic pipeline typically consists of 3 steps:
1) Extracting data from the source using Power Query
2) Transforming that data in Power Query
3) Loading that data into a Power BI dataset
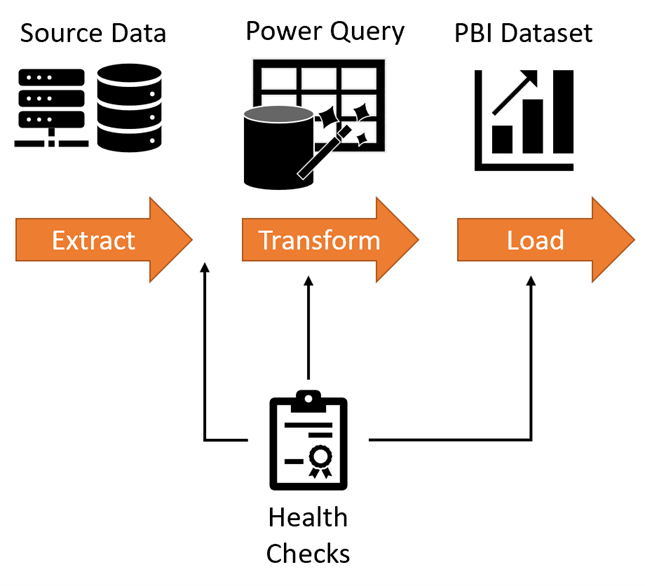
Figure 3 - Health checks should occur in a typical Power BI analytic pipeline.
According to the Quality is Paramount principle, you should check for issues throughout all three steps to reduce errors. However, implementing what I call health checks into pipelines is easier said than done. Power BI doesn’t offer an out-of-box health check tool yet (I’m hopeful Microsoft Fabric/Data Activator will close that loop soon). Until that happens, I typically recommend teams perform the following health checks for each step:
- Extract. Don't trust your upstream sources. You can check the source data for schema or content issues through several methods:
- Dataflows 1.0 -- Following the Medallion approach, you can initially ingest the source data in the bronze layer of the dataflow. Then, via a silver dataflow, you can import the data to conduct health checks. Finally, you would create the gold flow to feed a health check dataset and this dataset could be used to monitor for issues via a Power BI report.
- Dataflows 1.0 with Bring Your Own Data Storage -- If you have access to Bring Your Own Data Storage with Dataflows 1.0, you can inspect the schema and content using automated checks in Azure DevOps pipelines. I describe this approach in Part 21.
- Dataflows 2.0 -- Now this advice is for a product in preview at the time of this writing, and there may be changes in the final product. But as it stands, you can apply the Medallion approach described above and follow up with Notebooks to inspect the data and conduct health checks. I'll describe that approach in a future article (yep, a teaser).
- Transform. Automate error detection in the code used to transform data. To achieve this, teach your teams to perform the following:
- If you're allowed to quarantine data that doesn't meet expectations and would produce cell-level errors, I recommended reading Radacad's excellent article to create exception tables.
- If you cannot quarantine data, try implementing the *try/otherwise* M code within all your transform columns or adding custom column steps (see **Figure 4**). This step automatically handles exceptions and transforms the data into a more stable state.
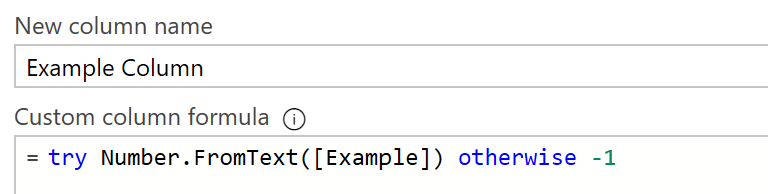 Figure 4 - Example of try/otherwise in M code.
Figure 4 - Example of try/otherwise in M code.
- Load. With any analytics pipeline, you should have an in-depth defense approach. Even if you implement checks during the Extract and Transform steps, mistakes can still happen. Here are ways to double-check for cell-level errors:
- ExecuteQuery -- With the custom connector I offered in Part 22, you can build a health check into the monitoring template and check for the existence of null values produced from a cell-level error. Using the ExecuteQuery function, you can identify null values with a DAX query (shown in **Figure 5** below) and raise those issues through a Power BI Report.
 Figure 5. Example DAX query.
Figure 5. Example DAX query. - Check for "Errors in" tables -- If your team encounters cell-level errors during development and chooses the "View Errors" option, a table prefixed with "Errors in" is created and hidden in the model.
 Figure 6 - Example of an "Errors in" table.* If this table is present, it might mean that the cell-level error has been resolved and the table can be deleted. Or, it might mean that the cell-level errors, and the issues causing them, still exist. With the latest version of the monitoring template, you can identify occurrences of the "Errors in" tables.
Figure 6 - Example of an "Errors in" table.* If this table is present, it might mean that the cell-level error has been resolved and the table can be deleted. Or, it might mean that the cell-level errors, and the issues causing them, still exist. With the latest version of the monitoring template, you can identify occurrences of the "Errors in" tables.
- ExecuteQuery -- With the custom connector I offered in Part 22, you can build a health check into the monitoring template and check for the existence of null values produced from a cell-level error. Using the ExecuteQuery function, you can identify null values with a DAX query (shown in **Figure 5** below) and raise those issues through a Power BI Report.
I hope this helps stop cell-level errors from reaching your production datasets. I’d like to hear your thoughts, so please let me know what you think on LinkedIn or Twitter.
Finally, if you’re going to be at the 365 EduCon in Washington D.C., June 12th-16th 2023, I’ll be presenting on Wednesday and Friday. I hope to see you there!
This article was edited by my colleague and senior technical writer, Kiley Williams Garrett.