DataOps Principle #8 - Reflect
As I stated in Part 26 of this ever-growing series (a real journey), my colleagues, clients, and I often live in a G3/E3 world. Because of this licensing model, SharePoint lists and document libraries become a big host for business applications. And what tool do we often use to report on these lists and document libraries? … you guessed it, Power BI. Yes, folks this is a Power BI and SharePoint article…again, so buckle up.
I regularly see SharePoint lists with lookups to other SharePoint lists and extensive customization of columns to mimic relational models for what could go into SQL Server or Dataverse (yes, I know SharePoint data is stored in some form of SQL, but for the sake of this conversation it’s not the same). Yet, because of the additional cost, many SharePoint users avoid switching to a different storage option. Furthermore, the additional cost they are willing to spend is often towards Power BI. This article does not provide an opinion on the reasons customers don’t move from SharePoint to Dataverse or Azure SQL, I’m more concerned with what that means to our Power BI projects. Over the past two years using iterations of monitoring, our team has been able to apply the DataOps principle of Reflect and look at what impacts our ability to deliver insights quickly.
DataOps Principle #8: Analytic teams should fine-tune their operational performance by self-reflecting, at regular intervals, on feedback provided by their customers, themselves, and operational statistics.
Through reflection, we’ve seen that customers provide two big expectations when combining SharePoint and Power BI:
Expectation #1 - When data is updated in a SharePoint list, I want it reflected as quickly as possible in the Power BI reports.
Expectation #2 - SharePoint has version history so I want to be able to run analytics in Power BI leveraging when list items change. For example, I'd like to know how long it takes for a SharePoint task to change from new to assigned.
It may be a little lengthy to address both expectations in one article, so I’ll focus on the first one for now.
Addressing Expectation #1
For Power BI projects this can be a big challenge because if you're importing SharePoint lists into your Power BI model, you may have experienced issues with existing connectors like:
1) The native v1 and v2 SharePoint list connectors are incredibly slow. I’ve seen refreshes take over two hours just to load multiple lists. This is often attributed to the “greediness” of the connector to pull all the columns (hidden and visible) into Power Query. In other words, the connectors aren't necessarily adhering to Roche’s Maxim of Data Transformation.
2) The OData connector could be faster, but it requires you to learn the SharePoint API and understand how to query the data. Learning how to use $expand and how to identify the internal names to choose which columns to bring into the model can be cumbersome. I’ve had many of a tutorial session with co-workers on why a SharePoint column has an internal name with the characters “x0020” in it.
3) The OData connector does not support relative URLs which makes parameterizing your workspace environments difficult. As described by The Seven Steps to Implement DataOps, parametrization is a key step.
Early in 2022, I offered an alternative custom m function with Web.Contents but after several implementations, I found the learning curve was just way too steep for most Power BI data analysts to learn the SharePoint API and understand the idiosyncrasies of working with internal SharePoint names. The steeper the curve, the longer it takes to deliver new Power BI reports and the less satisfied customers will be.
So, if I could find a way to write the API query for a data analyst, maybe we could eliminate the curve all together. After a few attempts, I’ve got a version available on a new repository at this link. The Power BI template in this release contains all the Power Query components you need.
I go more depth in the repository’s Readme but as illustrated in Figure 1 it works in 3 steps:
1) Via the fnGetFields function you identify the list you wish to query and are provided a curated table of the fields for that list.
2) You can then filter that table to the columns you want to retrieve.
3) Via the fnGetSharePointData function, you pass in the table and the function will build the query, issue the appropriate calls, get the SharePoint data, and expand the columns using the displays names.
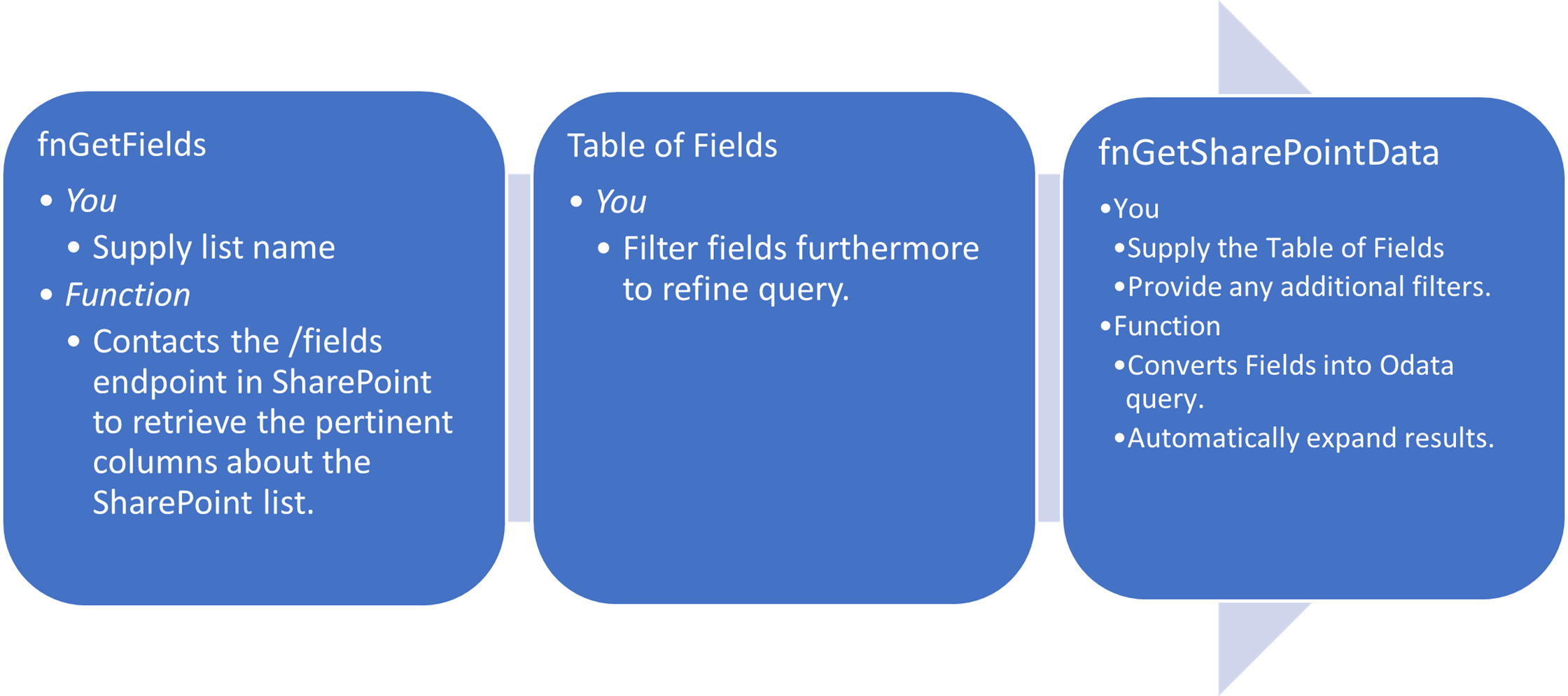
Figure 1 – 3 Steps to retrieve SharePoint data.
I ran this new version of the function against the other connectors using the same approach I described in Part 17. As shown in Figure 2, the bespoke version (the version I offer) ran faster than the other v1/v2 connectors in the PPU workspace and the Pro workspace (Figure 3). It scored slightly better than the OData connector and you don’t have to learn the SharePoint REST API with my bespoke version.
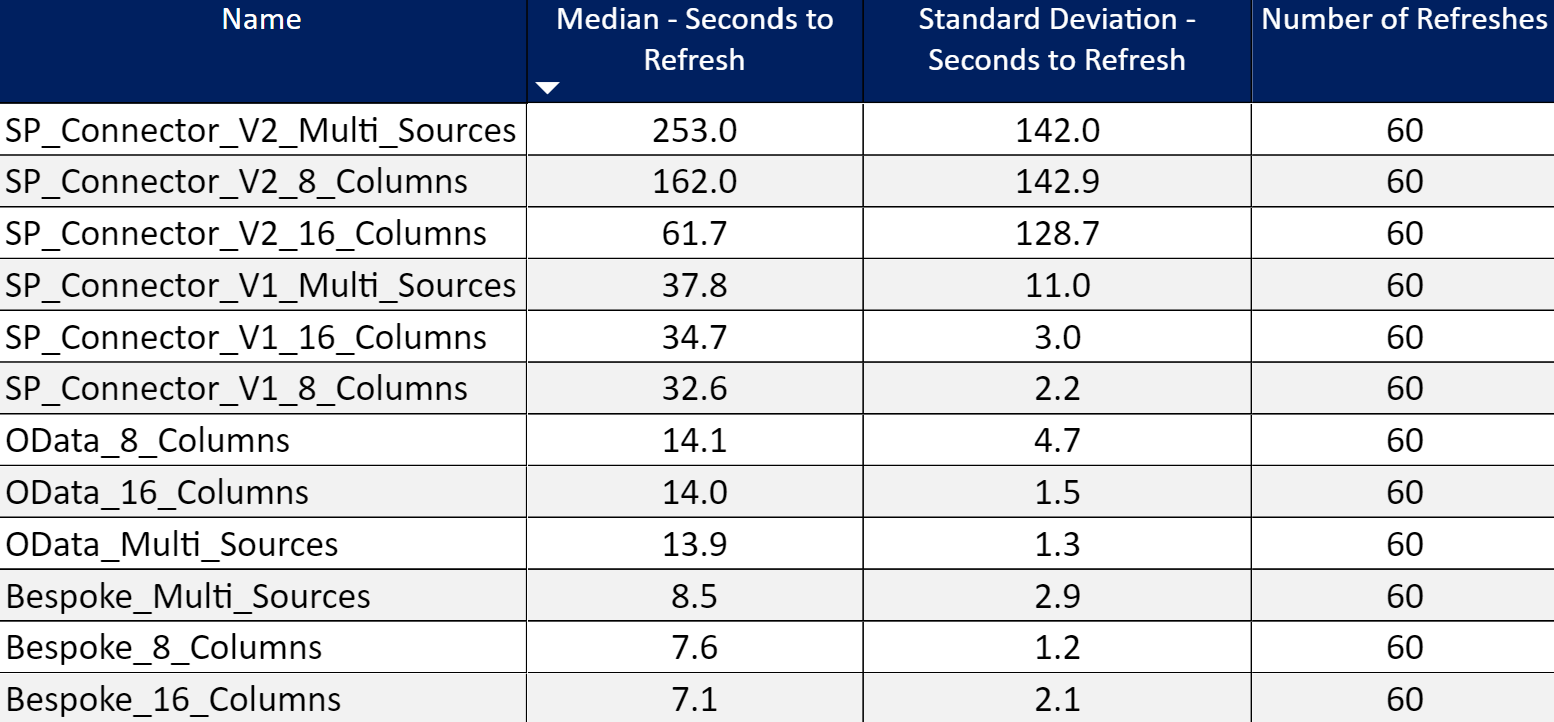
Figure 2 – Refresh Results in PPU workspace.
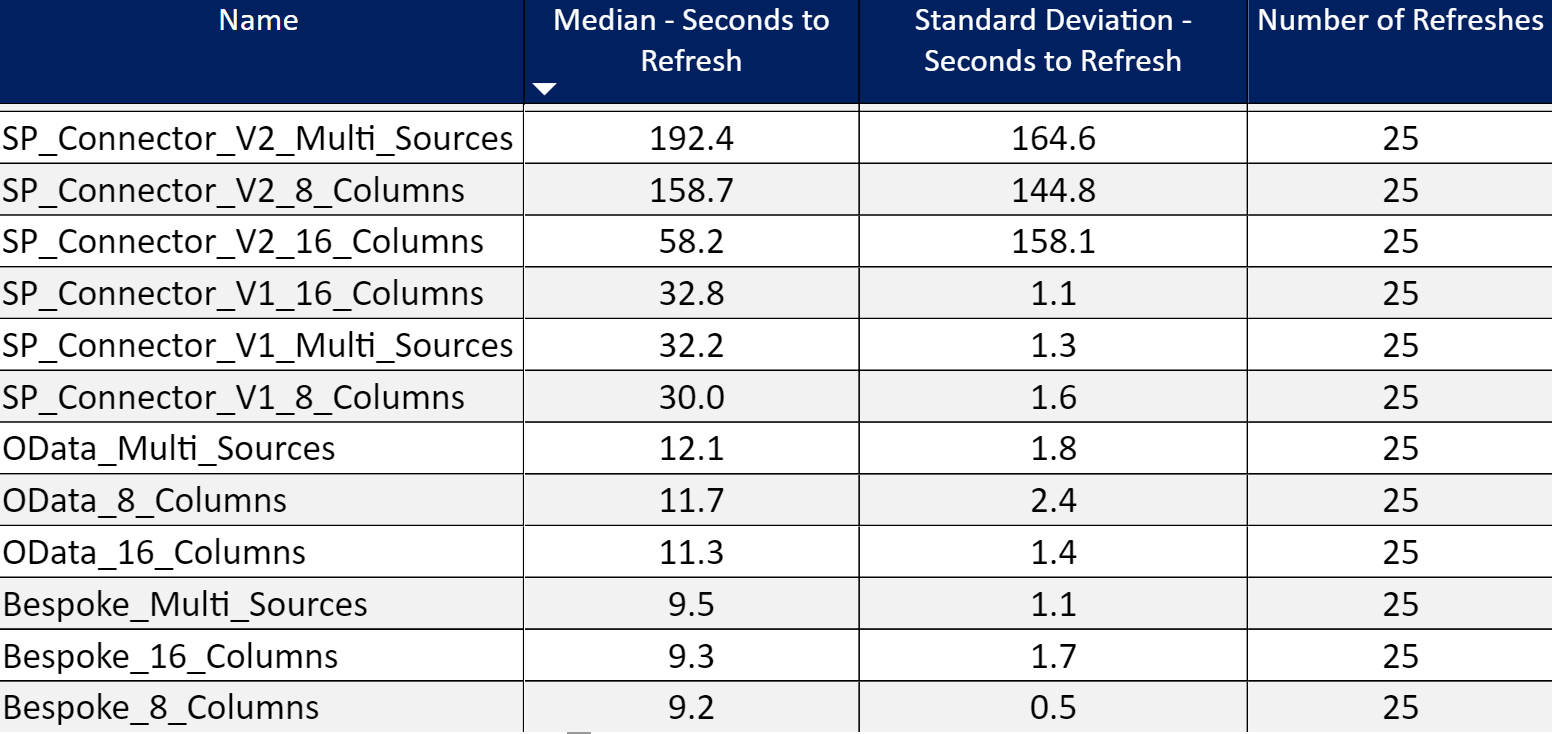
Figure 3 – Refresh Results in Pro workspace.
Please give it a try, and let me know what you think. If you got customizations on the fnGetFields or fnGetSharePointData, don't hesitate to fork the repository and experiment.
In my next post I’ll offer tips on Expectation #2 along with pulling in version history from a SharePoint list.